Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
Abstract
이번 논문에서 새로운 신경망 모델을 소개한다.
RNN Encoder-Decoder라는 이름으로 두개의 RNN으로 구성되어있다.
첫 번째 RNN은 symbol들의 sequnece를 고정된 길이의 vector 표현으로 인코딩하고,
다른 RNN은 그 vector를 다른 symbol들의 sequnce로 디코딩한다.
새로운 모델의 인코더와 디코더는 source sequece가 주어졌을 때
target sequence의 조건부 확률을 최대치로 만들도록 같이 학습된다.
Statistical machine translation 시스템의 성능은 경험적으로 이미 존재하는 log-linear model에서
추가적인 feature처럼 RNN Encoder-Decoder를 통해 구문의 쌍에 대한 조건부 확률을 계산하고
그것을 개선 시키는 것에 기반을 둔다.
질적으로 새로 고안된 모델이 의미와 문법적으로 의미있는 언어 구문들을 학습하는 것을 보여줄 것이다.
1 Introduction
심층 신경망들은 객체 인식과 음성인식 같은 다양한 곳에 적용했을 때 매우 좋은 성과를 보였다.
게다가 최근 많은 연구들은 신경망이 자연어처리(NLP) 작업들에서도 성공적으로 쓰일 수 있다는 것을 보였다.
이것들은 language modeling, paraphrase detection과 word embedding extraction도 포함한다.
Statistical machine translation(SMT) 분야 에서는 심층 신경망이 좋은 결과를 도출하기 시작 되했다.
Schwenk의 2012년도 논문에서는 feedforward 신경망이 구문 기만 SMT 시스템에서 잘 사용되었다고 발표했다.
SMT에 신경망을 사용한 Schwenk의 논문 내용과 같이,
이번 논문에서는 전통적인 구문기반 SMT 시스템에 한 부분으로 사용될 수 있는 새로운 신경망 구조에 집중할 것이다.
RNN Encoder-Decoder라 부르는 새로 고안된 신경망 구조는
encoder와 decoder 역할을 하는 두 RNN의 쌍으로 구성된다.
Encoder는 다양한 길이의 sourch sequence를 고정된 길이의 vector로 mapping하고
Decoder는 vector로 표현된 내용을 다시 다양한 길이의 target sequence로 mapping한다.
두 네트워크들은 source sequence가 주어졌을 때
target sequence의 조건부 확률을 극대화 시키도록 같이 학습된다.
게다가 memory capacity와 쉬운 학습을 위해 꽤 정교한 은닉 unit을 사용할 것을 제안한다.
새로운 hidden unit이 있는 RNN Encoder-Decoder는 경험적으로 English를 French로 번역하는 작업을 통해 평가된다.
영어 구문을 일치하는 프랑스어 구문으로 번역하도록 모델을 학습시킨다.
그렇게 되면 그 모델은 각 구문 쌍을 구문 테이블에서 점수를 비교하면서
기존 구문기반 SMT 시스템에 사용이 될 수 있다.
경험적인 평가에서는 RNN Encoder-Decoder를 통해 구문 쌍에 점수를 부여하는 접근은 번역 성능을 향상시켜줬다.
학습된 RNN Encoder-Decoder의 구문 점수를 이미 존재하는 번역 모델의 것과 비교해 질적으로 분석한다.
이러한 질적 분석으로 RNN Encoder-Decoder가 구문 테이블에서
언어의 일반성을 인지하는데 좋다는 것을 알 수 있고
이는 간접적으로 전반적인 번역 성능이 전량적으로 개선된다고 설명된다.
모델에 대해 더 분석을 해보니 RNN Encoder-Decoder가 지속적으로 구문의 구조에서
의미와 문법에 대한 정보를 가지고 있는 space representation을 학습하고 있다는 것을 알았다.
2 RNN Encoder-Decoder
2.1 Preliminary: Recurrent Neural Networks
Recurrent neural network (RNN)은 hidden state h와
다양한 길이의 sequence $\mathbf{x}=(x_1,\dots,x_T)$에 대해 선택적으로 갖는 output y로 구성된다.
각 time step $t$에서 RNN의 hidden state \(\mathbf{h}_{\left\langle t\right\rangle}\)가 아래 식을 통해 업데이트된다.
\(\begin{align}
\mathbf{h}_{\left\langle t\right\rangle}=
f\left(\mathbf{h}_{\left\langle t-1 \right\rangle},x_t \right)
\end{align}\)
여기서 f는 비선형 활성함수이다.
f는 element-wise logistic sigmoid function 만큼 단순하거나
LSTM unit만큼 복잡할 수도 있다.
RNN은 sequence의 다음 symbol을 예측하도록 학습되면서 sequence의 확률분포를 배울 수 있다.
이러한 경우에 각 time step $t$ 별로 출력값은 조건부 확률분포 (e.g, $p(x_t\ |\ x_{t-1},\dots,x_1)$)이다.
예를들어 multinomial distribution (1-of-K coding)은 softmax 활성함수를 이용해 출력값을 얻는다.
\(\begin{align} p(x_{t,j}=1\ |\ x_{t-1},\dots,x_1)= {\dfrac{\exp(\mathbf{w}_j\mathbf{h}_{\left\langle t\right\rangle})}{\sum\limits^K_{j\ '=1}\exp\left(\mathbf{W}_{j\ '}\mathbf{h}_{\left\langle t\right\rangle}\right)}} \end{align}\) 가능한 모든 symbol $j=1,\dots,K$에 대하여, $\mathbf{w}_j$는 가중치 매트릭스 $\mathbf{W}$의 row vector이다.
이 확률들을 조합하면 sequence $\mathbf{x}$의 확률을 구할 수 있다.
\[\begin{align} p(\mathbf{x})=\prod^T_{t=1}p(x_t\ |\ x_{t-1},\dots,x_1) \end{align}\]이렇게 학습한 분포로부터 각 time step에서 반복적으로 symbol을 샘플링함으로써 새로운 sequence를 제대로 샘플링 할 수 있다.
2.2 RNN Encoder-Decoder
이 논문에서 다양한 길이의 sequence를 고정된 길이의 vector 표현으로 encode하고
그 고정된 길이의 vector 표현을 다시 다양한 길이의 sequence로 decode하도록
학습한 새로운 구조의 신경망을 설명한다.
확률적인 관점에서 이 새로운 모델은 어떤 가변길이 sequence로부터 조정된
새로운 가변길이 sequence의 조건부 확률분포를 배우는 일반적인 방법이다.
e.g. $p(y_1,\dots,y_{T’}\ |\ x_1,\dots,x_T)$
여기서 입력 sequence의 길이인 $T$와 출력 sequence의 길이인 $T’$의 값은 다를 수 있다.
Encoder는 입력 sequence $\mathbf{x}$의 각 symbol을 순차적으로 읽는 RNN이다.
Encoder가 각 symbol을 읽듯이 RNN의 hidden state는 아래 식을 통해 변한다.
Sequence의 마지막(end-of-sequence symbol로 표시됨)까지 읽고 나면,
RNN의 hidden state는 전체 입력 sequence c의 요약본이 된다.
새로운 모델의 decoder는 또다른 RNN으로 주어진 hidden state \(\mathbf{h}_{\left\langle t \right\rangle}\) 를 가지고
다음 symbol $y_t$를 예측함으로써 output sequence를 만들도록 학습된다.
그러나 2.1절에서 말한 내용과 달리 $y_t$ 와 \(\mathbf{h}_{\left\langle t \right\rangle}\) 들은 $y_{t-1}$과 입력 sequence의 요약 c에의해 조정된다.
따라서 time t에서의 decoder의 hidden state는 아래와 같이 계산된다.
\[\begin{align*} \mathbf{h}_{\left\langle t\right\rangle}= f\left(\mathbf{h}_{\left\langle t-1\right\rangle},y_{t-1},\mathbf{c} \right) \end{align*}\]비슷하게 다음 symbol의 조건부 분포는 아래와 같다.
\[\begin{align*} P\left(y_t\ |\ y_{t-1},y_{t-2},\dots,y_1,\mathbf{c} \right)= g\left(\mathbf{h}_{\left\langle t\right\rangle},y_{t-1},\mathbf{c} \right) \end{align*}\]여기서 f와 g는 주어진 활성함수이고 g는 softmax같은 것을 사용해 반드시 합당한 확률값을 반환해야한다.
Fig 1을 보면 새로 고안된 모델의 구조를 그림으로 표현한 것을 볼 수 있다.
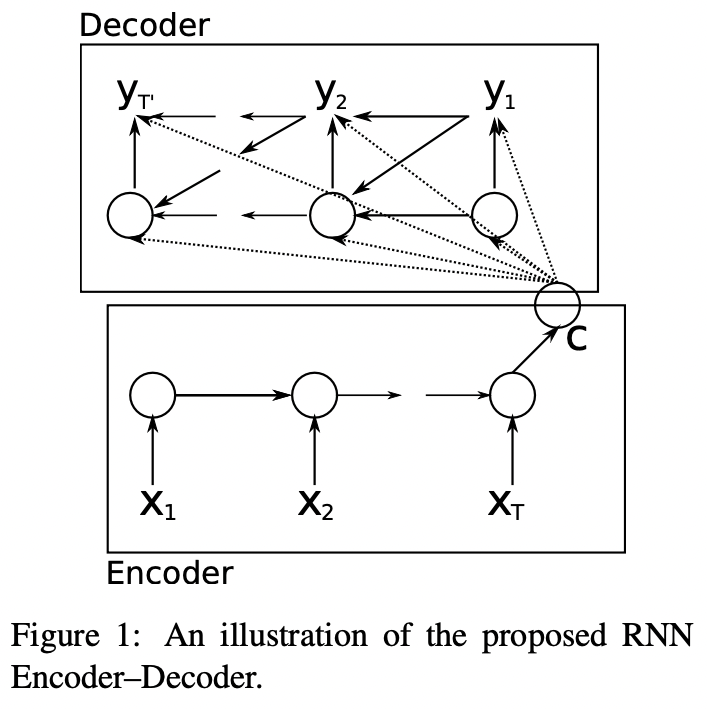
RNN Encoder-Decoder에을 구성하는 두가지 RNN은
conditional log-likelihood를 극대화 시키도록 함께 학습된다.
$\theta$는 모델 파라미터들의 집합이고 각 $(\mathbf{x}_n,\mathbf{y}_n)$는 (input sequence, output sequence) 쌍으로
training set에서 가져온다.
여기서는 decoder의 출력으로써 입력 처음부터 미분 가능하기 때문에
gradient 기반 알고리즘을 사용하여 모델 파라미터를 평가한다.
일단 RNN Encoder-Decoder가 학습된다면, 모델은 두가지 방법으로 사용될 수 있다.
하나는 모델을 input sequence가 주어졌을 때 target sequence를 만들기 위해 사용하는 것이다.
다른 하나는 모델을 식3,4를 이용해 간단하게 $p_\theta(\mathbf{y}\ |\ \mathbf{x})$를 점수로
input과 output sequence의 쌍을 점수화하기 위해 사용하는 것이다.
2.3 Hidden Unit that
Adaptively Remembers and Forgets
새로운 모델 구조에 추가적으로 새로운 타입의 hidden unit (식1의 $f$)을 생각했다.
새로운 hidden unit은 LSTM unit으로부터 영감을 받았지만 그보다 더 쉽게 계산되고 쉽게 구현할 수 있다.
Fig2 에서는 hidden unit을 그림으로 묘사했다.
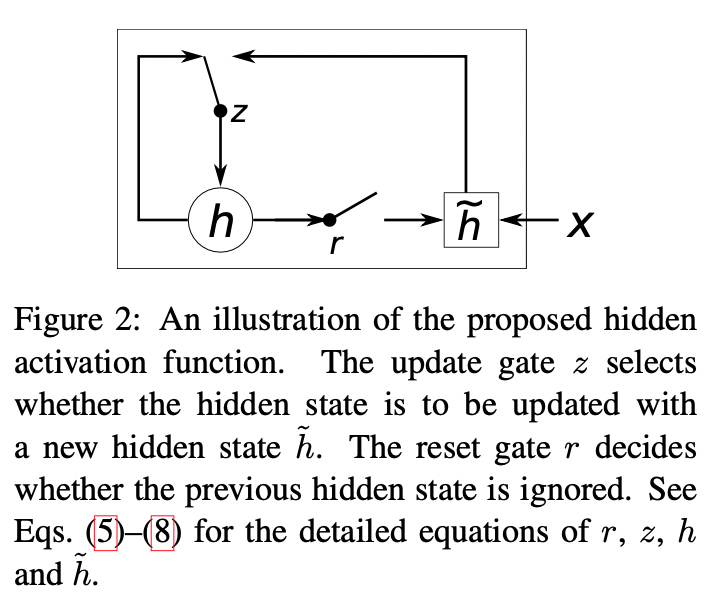
j 번째 hidden unit이 어떻게 계산되는지 알아보겠다.
먼저 reset gate $r_j$는 아래와 같이 계산된다.
여기서 $\sigma$는 logistic sigmoid 함수이고 \([.]_j\) 는 vector의 j 번째 원소를 뜻한다.
$\mathbf{x}$는 입력이고 $\mathbf{h}_{t-1}$는 이전 hidden state이다.
$\mathbf{W}$와 $\mathbf{U}$는 학습되는 가중치 매트릭스이다.
비슷하게 update gate $z_j$는 아래와 같이 계산된다.
\[\begin{align} z_j= \sigma\left(\left[\mathbf{W}_z\mathbf{x} \right]_j+ \left[\mathbf{U}_z\mathbf{h}_{\left\langle t-1\right\rangle} \right]_j \right) \end{align}\]그리고 unig $h_j$의 실제 활성은 아래를 통해 이루어진다.
\[\begin{align} h^{\left\langle t\right\rangle}_j=z_jh^{\left\langle t-1\right\rangle}_j+ (1-z_j)\tilde{h}^{\left\langle t\right\rangle}_j\\ \tilde{h}^{\left\langle t\right\rangle}_j= \phi\left(\left[\mathbf{Wx}\right]_j+ \left[\mathbf{U}\left(\mathbf{r}\odot\mathbf{h}_{\left\langle t-1\right\rangle} \right) \right]_j \right) \end{align}\]위 식들을 통해 reset gate가 0에 가까워지면 hidden state가 previous hidden state를 무시하고
현재 입력 만으로 재설정된다.
이러한 과정은 hidden state가 앞으로 관련성이 없는 정보를 drop시켜서 효과적으로 더 알찬 표현을 만들도록 한다.
다른 한편으로는 update gate가 이전 hidden state로부터 현재 hidden state로
정보를 얼만큼 전달할 것인지 조절하는데
이러한 활동이 LSTM의 memory cell이 하던 것과 비슷하고
RNN이 long-term 정보를 기억하게 해준다.
게다가 이러한 것은 leaky-integration unit의 다양성에 적응을 고려했다고도 볼 수 있다.
각 hidden unit이 분리된 reset gate와 update gate를 갖는 것처럼
각 hidden unit은 다른 time scale들에서 의존성을 포착하도록 학습할 것이다.
short-term 의존성을 포착하도록 학습된 이 unit들은 자주 활성화된는 reset gate를 갖는 경향을 보일 것이다.
하지만 longer-term 의존성을 포착하는 것들은 자주 활성화되는 update gate를 갖게 될 것이다.
사전 실험에서 이 새로운 unit을 gating unit들과 사용하는 것이 중요하다는 것을 알아냈다.
이런 gating unit 없이 자주 사용되는 tanh 만으로는 의미 있는 결과를 낼 수 없었다.
3 Statistical Machine Translation
보통 사용되는 Statistical machine translation system(SMT)에서
시스템(특히 decoder)의 목적은 아래 값을 극대화 시키며 주어진 source sentence e를 통해 번역된 f를 찾는 것이다.
오른쪽 부분에서 첫 번째 항은 translation model이고 뒤에는 language model이다.
하지만 사실 대부분의 SMT 시스템들은 추가적인 feature와 일치하는 가중치들로
log-linear 모델처럼 $\log\ p(\mathbf{f}\ |\ \mathbf{e})$를 이용한다 :
$f_n$은 n 번째 feature를 뜻하고 $w_n$은 n 번째 가중치를 뜻한다.
$Z(\mathbf{e})$는 정규화 상수로 가중치의 영향을 받지 않는다.
가중치들은 BLEU 점수를 최대화하기 위해 자주 최적화된다.
구문 기반 SMT 프레임워크에서는 번역 모델 \(\log p(\mathbf{e}\ \vert\ \mathbf{f})\)는
source sentence와 target sentence의 번역 확률로 분해된다.
이러한 확률들은 식9를 이용해 다시 한번 log-linear모델에서 추가적인 feature들을 고려한다.
또한 BLEU 수치를 최대화하기 위해 가중치가 적용된다.
언어모델을 위한 신경망이 제안되었기 때문에,
신경망들은 SMT 시스템에서 널리 사용되게 되었다.
많은 경우에 신경망들은 번역을 하기 위한 가정들을 새로 점수를 게산한다. (n-best lists)
그러나 최근에는 source sentence의 표현을 추가적인 입력으로 사용하여
구문 쌍이나 번역된 문장에 점수를 부여해 신경망을 학습 시키는 방법에 관심이 모이고있다.
3.1 Scoring Phrase Pairs with RNN Encoder-Decoder
2.2절에서 말한 RNN Encoder-Decoder를 구문 쌍에 대한 테이블에서 학습시키고
SMT decoder를 튜닝할 때 식9를 이용해 log-linear 모델에서 그 테이블의 점수들을 추가적인 feature로 사용한다.
RNN Encoder-Decoder를 학습 시킬 때,
원래 글의 내용에서 각 구문 쌍의 정규화된 빈도수를 무시한다.
이러한 방법은 정규화된 빈도수에 따라 큰 구문 테이블로부터 구문 쌍을 임의로 골라 계산하는 비용을 줄이고
RNN Encoder-Decoder가 단순히 구문 쌍을 그것의 출현 횟수로만 순위를 매기는 것이 아님을 보장한다.
이러한 선택에 대한 기저에 깔린 한가지 이유는
구문 테이블에서 번역 가능성의 존재는 이미 입력된 본문에서 구문쌍의 빈도수를 반영한 것이다.
고정된 RNN Encoder-Decoder의 용량에서
모델의 대부분의 용량은 언어의 규칙성을 학습하는데에 초점을 두려고 했다.
언어의 규칙성이란 다시말해 잘 번역된것과 잘 번역되지 않은 것을 구별하는것 또는
잘 번역된 다양한것을 배우는것을 뜻한다.
일단 RNN Encoder-Decoder가 학습되면 이미 존재하는 구문 테이블의 각 구문 쌍에 새로운 점수를 추가한다.
이것은 새로운 점수들이 계산량을 조금 추가하여 존재하는 튜닝 알고릴즘에 적용되도록 한다.
Schwenk가 말하길 이미 존재하는 구문 테이블을 고안된 RNN Encoder-Decoder로 대체하는 것이 가능하다고 한다.
그런 경우 주어진 source 구문에서 RNN Encoder-Decoder는
좋은 target 구문의 리스트를 만들 필요가 있을 것이다.
그러나 이것은 반복적으로 수행되는 샘플링 과정이 매우 expensive할 것이다.
그러므로 이 논문에서 구문 테이블에서 구문 쌍들을 다시 점수를 매기는것만 고려하려고 한다.
3.2 Related Approaches: Neural Networks in Machine Translation
경험적인 결과를 발표하기 전에, 우리는 문맥 SMT에서 신경망을 사용하도록 제안하는 수많은 연구들을 살펴봤다.
Schwenk는 2012년에 구문 쌍에 점수를 매기는 것과 비슷한 접근법을 제안했다.
RNN 기반 신경망 대신에 그는 고정된 크기의 입력(그의 경우 짧은 구문은 zero-padding을 하면서
7개의 단어를 받는다)을 받고 target 언어로 7개의 단어로 구성된
고정된 크기위 출력을 갖는 feedforward 신경망을 사용했다.
이 feedforward 신경망이 SMT 시스템에서 구문에 점수를 매기는데 사용되는 경우에
가장 긴 구문은 종종 짧은 것으로 선택된다.
그러나 구문의 길이가 길어지거나 다른 가변 길이의 sequence data에 신경망을 적용하기 때문에,
신경망이 가변 길이의 입력과 출력을 다루는 것은 중요하다.
여기서 제안된 RNN Encoder-Decoder는 이러한 적용에 잘 들어맞는다.
2012년도의 Schwenk와 비슷하게 2014년에 Devlin이 feedforward 신경망을 번역 모델을 만드는데 사용했고
target 구문에서 한번에 한 단어를 예측하는 모델이었다.
그들은 인상적인 개선을 보였지만 그들의 접근은 여전히 사전에 고정된 입력 구문의 최대 길이를 필요로 했다.
비록 그들이 학습시킨 것은 완전히 신경망은 아니지만,
2013년의 Zou의 논문의 저자들은 단어나 구문 embedding에서
두 언어를 자유롭게 구사하도록 학습시킬 것을 제안했다.
그들은 SMT 시스템에서 구문 쌍의 점수들을 추가적으로 사용하여
구문들의 쌍 사이에 거리를 계산해 embedding하도록 학습 시켰다.
2014년에 Chandar의 논문에서는 feedforward 신경망을
입력 구문의 표현인 bag-of-words에서 출력 구문으로 mapping 하도록 학습시켰다.
이 내용은 그들이 입력 구문의 표현을 bag-of-words로 사용한 것을 제외하면
RNN Encoder-Decoder와 2012년에 Schwenk가 제안한 모델과 매우 유사했다.
Bag-of-words를 사용한 비슷한 접근은 2013년 Gao의 논문에서 등장했다.
이전에 2011년에 Socher가 encoder-decoder 모델과 비슷하게 두가지 RNN을 사용했었지만
그들의 모델은 한가지 언어에 대한 설정(모델이 input sequence를 다시 만드는 방식)으로 한정되어 있었다.
더 최근에는 또다른 RNN을 사용하는 encoder-decoder 모델이 2013년에 Auli의 논문에서 제안되었다.
여기서 decoder는 source sentence와 source context에 의해 조정되었다.
RNN Encoder-Decoder와 두가지 논문(2013년의 Zou의 논문과 2014년의 Chandar의 논문)
사이에 한가지 중요한 차이점은
source와 target 구문의 단어들의 순서를 고려한다는 것이다.
앞서 말한 접근들은 순서에 대한 정보를 효과적으로 무시하는 반면에
RNN Encoder-Decoder는 자연스럽게 같은 단어를 갖는 문장이더라도 순서가 다른 문장들을 서로 구분한다.
여기서 제안하는 RNN Encoder-Decoder와 가장 비슷한 접근법은
2013년에 Kalchbrenner와 Blunsom이 제안한 Recurrent Continuous Translation Model(Model 2)이다.
그들의 논문에서 그들은 encoder와 decoder로 구성된 비슷한 모델을 제안했다.
우리 모델과의 차이점은 그들은 convolutional n-gram model (CGM)을 encoder로 사용하고
CGM의 inverse 버전과 RNN을 합친것을 decoder로 사용했다.
그러나 그들은 그들의 모델을 전통적인 SMT 시스템의 n-best list의 점수를 다시 매기면서 평가하도록 제안했고
그 기준 번역의 PPL을 계산했다.
4 Experiments
우리의 접근 방법을 WMT’14 workshop의 영어/프랑스어 번역 작업을 통해 평가했다.
4.1 Data and Baseline System
WMT’14 번역작업의 프레임워크에서는 영어/프랑스어 SMT시스템이 만들어지도록 많은 양의 데이터를 사용할 수 있다.
두가지 언어를 자유롭게 구사하는 본문은 Europarl(61M 단어들), news comentary (5.5M), UN (421M) 그리고 두개의 crawl된 말들이 90M과 780M 만큼 포함되어있다.
마지막 두개의 본문은 꽤 noisy하다.
프랑스어 모델을 학습 시키기 위해,
712M개의 신문 자료로부터 crawl된 단어들을 bitext의 target side에서 추가로 사용가능하다.
모든 단어들의 횟수는 tokenization 후에 프랑스 단어를 가리킨다.
모든 데이터들을 연결해서 만든 데이터로 확률적 모델들을 학습시키는 것은 최적의 성능으로 무조건 이끌지 않고
다루기 힘든 극도로 큰 모델들의 결과를 만든다.
대신에 주어진 작업에서 데이터의 가장 관련있는 하위집합에서 집중해야하는 것은
2010년 Moore와 Lewis의 방법으로 데이터를 선택적으로 적용하고
2011년 Axelrod처럼 bitext로 확장시켰었다는 것이다.
이것은 우리가 RNN Encoder-Decoder를 학습 시키기 위해 850M 중 348M개의 단어를 갖는 하위 집합을 택하고
2G중 418M개의 단어를 갖는 하위집합을 택했다는 것이다.
Test set newtest2012와 newtest2013를 데이터 선택에 사용하고
가중치 튜닝은 MERT로 하고 test set으로 newtest2014를 사용했다.
각 집합은 7만개가 넘는 단어를 갖고 single reference translation도 갖는다.
RNN Encoder-Decoder와 신경망을 학습하기 위해,
우리는 source와 target vocabulary를 가장 많이 등장하는 15000개의 단어들로
영어와 프랑스어에 모두 제한을 두었다.
이 범위는 데이터셋의 93%를 차지하는 범위이다.
vocabulary에 있지 않은 모든 단어들은 special token ([UNK])로 mapping했다.
구문 기반 SMT 시스템의 기반은 Moses를 통해 기본설정을 사용해 만들었다.
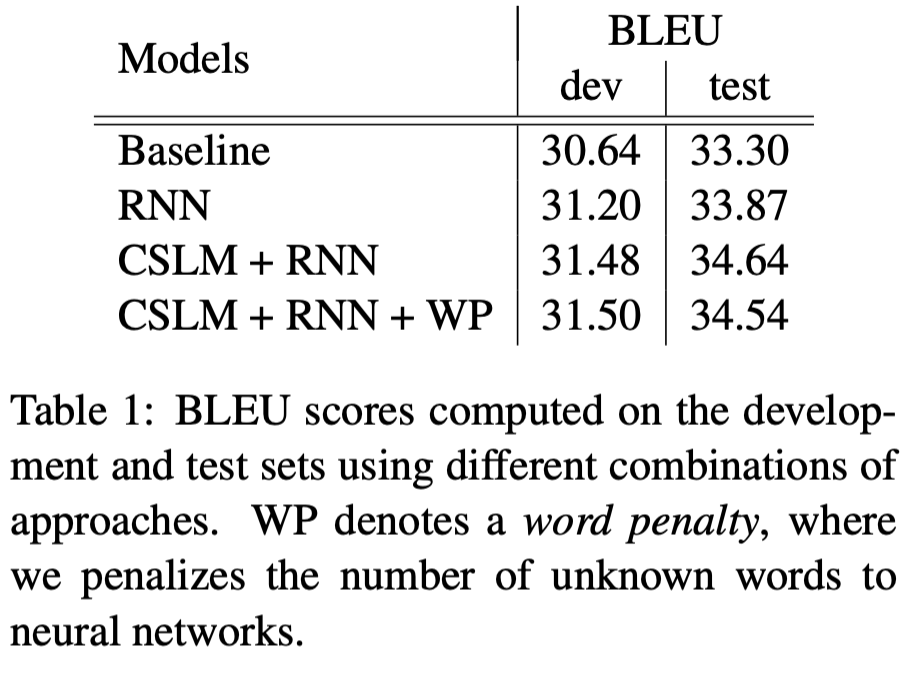
이 시스템 구조는 개발과 test set에서 각각 BLEU 점수를 30.64와 33.3를 달성했다.
4.1.1 RNN Encoder-Decoder
실험에서 사용된 RNN Encoder-Decoder는 encoder와 decoder에서
1000개의 hidden unit과 제안된 gate를 사용했다.
입력 symbol $x_{\left\langle t\right\rangle}$와 hidden unit 사이의 입력 매트릭스는 두개의 low-rank matrices로 나뉘고
output matrix도 비슷하다.
rank-100 매트릭스를 사용했고 이는 각 단어를 100차원으로 임베딩하도록 학습하는 것과 같다.
식8에서 $\tilde{h}$ 계산을 위해 사용된 활성 함수는 tanh함수이다.
decoder에서 hidden state에서 출력으로 계산하는 것은 2014년 Pascanu의 심층 신경망 작업처럼
단일 중간층을 가지는데 그 중간층에는 2개의 입력을 pooling하여 500개의 maxout unit을 통해 구현했다.
RNN Encoder-Decoder의 모든 가중치 파라미터들은 가우시안 분포를 따르는
표준편차가 0.01이고 평균이 0인 상태에서 샘플링하여 초기화를 했고 recurrent weight parameters는 예외이다.
Recurrent weight parameters의 경우에는 먼저 가우시안 분포에서 샘플링하고 남은 singular vectors matrix를 사용했다.
Adadelta와 SGD를 RNN Encoder-Decoder를 학습하기 위해 사용했고
하이퍼파라미터는 $\epsilon=10^{-6}, \rho=0.95$를 사용했다.
각 엄데이트에서는 348M개의 단어들로 만든 구문 테이블에서 구문쌍을 임의로 64개 골라서 사용했다.
모델 학습에는 대략 3일이 걸렸다.
실험에서 사용된 구조의 자세한 내용은 보충 자료에 더 깊이있게 서술했다.
4.1.2 Neural language Model
RNN Encoder-Decoder가 구문 쌍에 점수를 매기는 것의 효과를 평가하기 위해,
target language model을 학습하기 위해 신경망을 사용해 더 전통적인 접근 방법을 사용했다.(CSLM)
특히, CSLM을 사용한 SMT 시스템과 RNN Encoder-Decoder를 이용해 구문에 점수를 매기는 방법을
사용하는 것에 대한 비교는 여러개의 신경망이 SMT 시스템이 풍부해지도록
다른 부분에 기여하는 정도에 따라 명확해질 것이다.
CSLM 모델을 target 본문의 7-grams에서 학습시켰다.
각 입력 단어는 $\mathbb{R}^{512}$ 임베딩 공간으로 사영을 시켰고,
그것들을 이어 붙여서 3072차원의 벡터를 형성했다.
연결된 벡터는 두개의 rectified layer(1536과 1024 크기인)로 입력되었다.
output layer는 간단한 softmax 층이다.
모든 가중치 파라미터들은 똑같이 -0.01과 0.01 사이에서 초기화 시켰고
모델은 validation perplexity가 10 epoch동안 더 개선되지 않을 때까지 학습시켰다.
학습이 끝나고 언어 모델은 45.80 PPL을 달성했다.
Validation set은 본문의 0.1%를 임의로 골라 사용했다.
모델은 n-best list rescoring보다 BLEU 점수를 더 받도록 decoding 과정에서
부분적 번역에 점수를 측정하는데 사용했다.
decoder에서 CSLM의 사용으로 인한 계산 복잡도 문제를 해결하기 위해
buffer를 사용해 decoder가 stack-search를 수행하는 동안 n-grams를 합쳤다.
buffer가 차거나 stack이 삐뚤어진 경우에만 n-grams가 CSLM에 의해 점수를 받는다.
이것은 Theano를 사용하는 GPU에서 matrix-matrix 곱연산을 빠르게 하도록 해준다.
4.2 Quantitative Analysis
아래와 같은 조합을 사용했다.
- Baseline configuration
- Baseline + RNN
- Baseline + CSLM + RNN
- Baseline + CSLM + RNN + Word penalty
결과는 아래와 같다.
예상했던 대로, 신경망에 의해 계산된 feature들을 추가하는 것은
꾸준히 baseline 성능을 넘어 개선되었다.
가장 좋은 성능은 CSLM과 RNN Encoder-Decoder를 모두 사용 했던 경우였다.
이러한 내용은 CSLM과 RNN Encoder-Decoder의 기여도는 서로 지나치게 영향을 주지 않고
독립적으로 각 방법을 개선함으로써 더 좋은 결과를 기대할 수 있다는 것을 말해준다.
게다가 신경망이 모르도록 단어의 수를 제한했다.
우리는 단순히 식9에서 log-linear모델이 추가적인 feature로 unknown 단어의 수를 추가했다.
그러나 이런 경우에 우리들은 test set에서 좋은 성능을 얻지 못했지만
development set에서는 얻을 수 있었다.
4.3 Qualitative Analysis
성능 개선이 어디서부터 이루어지는지 이해하기 위해,
우리는 구문 쌍의 점수를 RNN Encoder-Decoder를 통해 translation model로부터 $p(\mathbf{f}\ \vert\ \mathbf{e})$를 계산했다.
이미 존재하는 translation model은 오로지 본문의 구문 쌍의 통계에 의존하기 때문에,
우리는 그것의 점수들을 많이 등장하는 구문에 좋은 평가가되고
드물게 등장하는 구문에는 안좋게 평가가 될것이라 예상했다.
또한 앞서 3.1절에서 말한 것처럼 빈도에 대한 정보를 빼고 구문 쌍에 점수를 매기는 RNN Encoder-Decoder는
본문에서 구문의 확률적 등장보다 언어의 규칙성에 기반을 둘것이라 생각한다.
source 구문이 3단어 이상으로 이루어진 긴 source 구문의 쌍과 자주 등장하는 쌍에 초점을 둔다.
이러한 각 source 구문들인 경우 우리는 target 구문에서
번역 확률 $p(\mathbf{f}\ \vert\ \mathbf{e})$ 또는 RNN Encoder-Decoder에서 높은 점수를 받는 것을 찾는다.
비슷하게, 길지만 빈도가 낮은 source 구문의 구문 쌍에 대해서도 같은 처리과정을 수행한다.
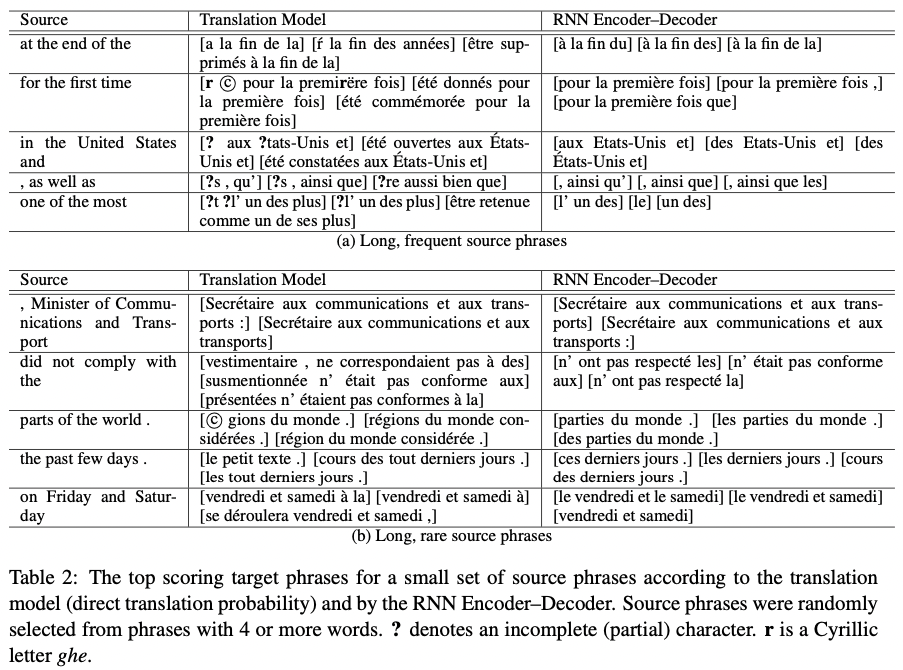
Table 2는 source 구문에 대하여 translation model과 RNN Encoder-Decoder가
가장 선호하는 target 구문을 3개씩 고른 것이다.
Source 구문들은 4개나 5개 이상의 단어들을 갖는 긴 구문들 중에서 임의로 고른 것이다.
대부분의 경우에 RNN Encoder-Decoder의 target 구문들을 선택하는 것은 실질적이거나 문헌적 번역과 비슷하다.
우리는 일반적으로 RNN Encoder-Decoder가 짧은 구문을 선호하는 것을 관찰했다.
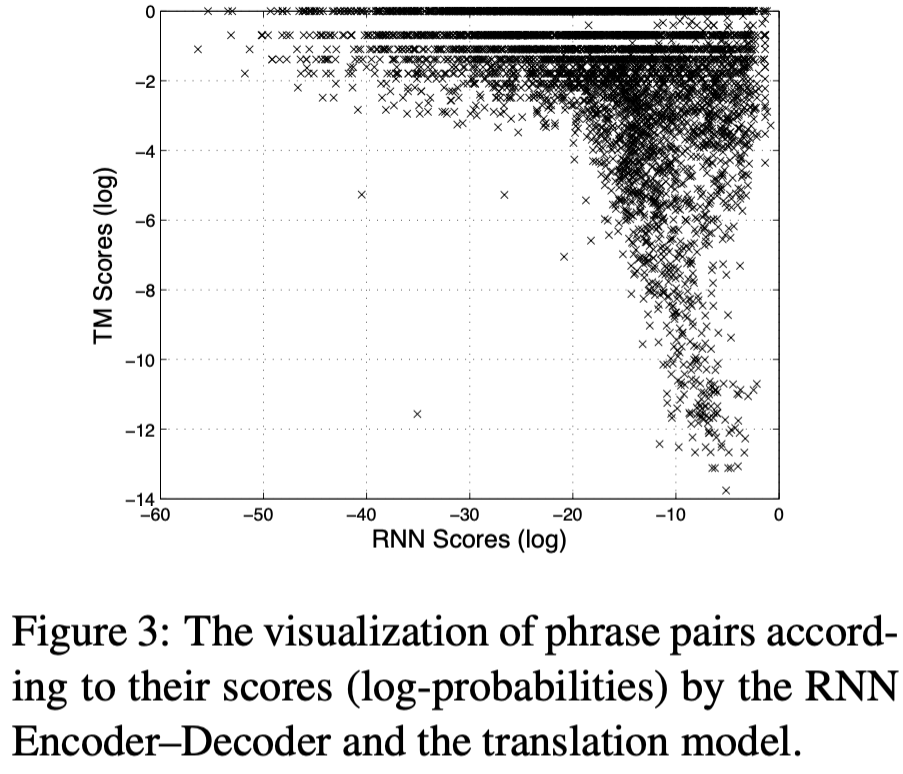
흥미로운 것은 많은 구문 쌍들이 translation model과 RNN Encoder-Decoder에 의해 비슷한 방법으로 매겨졌지만 근본적으로 다른 점수를 갖는 구문 쌍들도 있었다.(Fig3 참조)
이것은 앞서 설명했듯이 RNN Encoder-Decoder가 단순히 본문에서 구문 쌍의 빈도수를 학습하지 않고 유일한 구문 쌍을 학습하는 접근 방식 때문에 생길 수 있다.

게다가 Table3 에서는 RNN Encoder-Decoder로부터 반들어진 Table2 의 source 구문을 보인다.
각 source 구문은 그들의 점수에 따라 50개의 샘플들을 만들어 가장 좋은 5개의 구문을 골랐다.
여기서 RNN Encoder-Decoder가 실제 구문 테이블을 보지 않고
target 구문을 잘 만들어 제안하는 것을 볼 수 있었다.
중요한건 이렇게 만들어진 구문들은 구문 테이블의 target 구문과 전혀 겹치지 않는다는 것이다.
이것은 우리가 구문 테이블의 일부나 전체를 앞으로 RNN Encoder-Decoder가 제안하는 것으로 대체할 가능성을 조사해볼만 하다고 느끼게 한다.
4.4 Word and Phrase Representations
RNN Encoder-Decoder는 기계 번역을 위해서만 설계된 것이 아니기 때문에,
학습된 모델의 특성을 간단하게 살펴보겠다.
신경망을 사용하는 연속적인 공간의 언어 모델들은
뜻에 대해 의미가 있는 embedding을 학습 할 수 있다고 알려져있다.
RNN Encoder-Decoder가 projection을 하고
단어들의 sequence로부터 다시 연속적인 벡터 공간으로 mapping하기 때문에,
제안된 모델에서 비슷한 속성을 관찰할 것이라 예상했다.
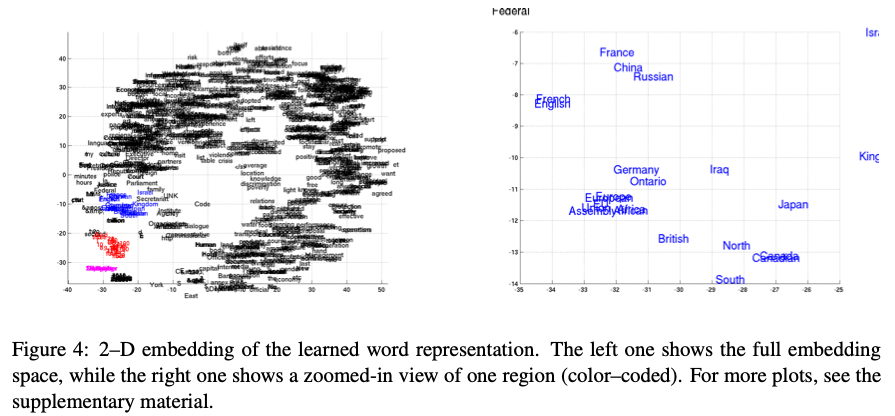
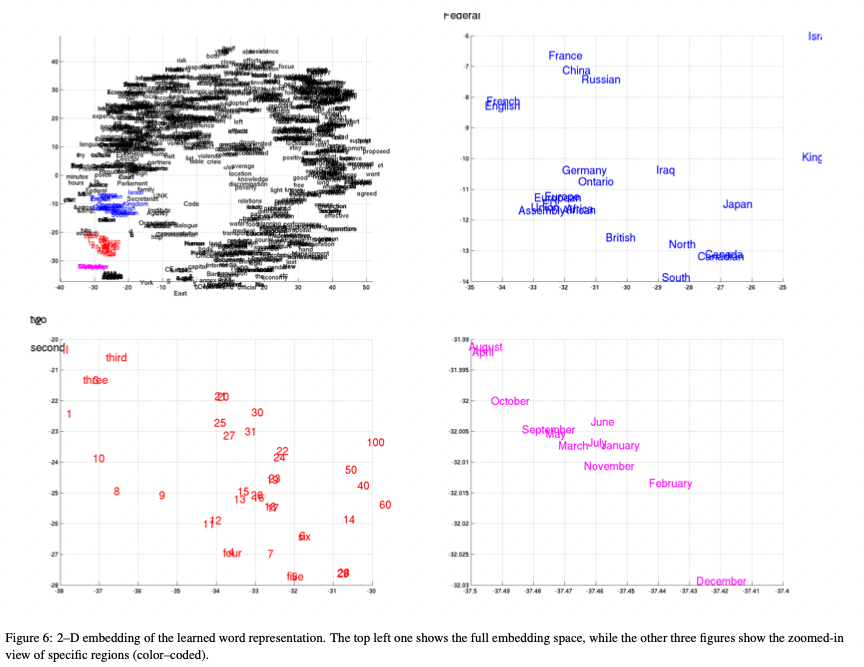
Fig4에서 왼쪽 부분은 RNN Encoder-Decoder로부터 학습한
word embedding matrix를 사용해 만든 2-D 임베딩을 보여준다.
Projection은 2013 van der Maaten의 논문에서 제안한 Barnes-Hut-SNE를 따라 했다.
우리는 정확하게 의미적으로 비슷한 단어들이 서로 군집을 형성하는 것을 확인했다.(Fig4의 확대된 그림을 봐라)
RNN Encoder-Decoder는 자연적으로 구문의 표현을 연속된 공간으로 만들어낸다.
Fig1의 c의 표현은 1000차원의 벡터이다.
단어의 표현도 비슷하게, 우리는 Fig5에서 Barnes-Hut-SNE를 사용해 4개 이상의 단어들로 구성된 구문의 표현을 시각화 했다.
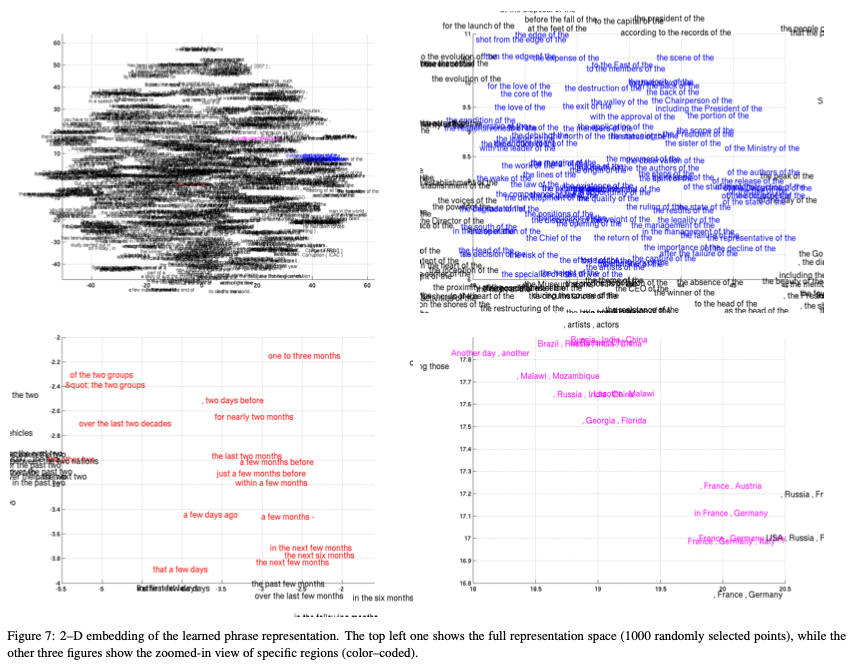
이 시각화로부터,
RNN Encoder-Decoder가 구문의 의미적인 내용과 문법적인 내용의 구조를 파악한다는 것이 명확해졌다.
예를 들어, 왼쪽 아래 그림에서, 문법적으로 비슷하고 대부분의 구문들은 시간에 대한 내용을 표현하는 것들끼리 군집을 형성하고 있다.
오른쪽 아래 그림에서는 의미적으로 비슷한(국가나 지역) 구문의 군집을 보여주고 있다.
다른 한편으로, 오른쪽 위 그림에서는 문법적으로 비슷한 구문들을 보여준다.
5 Conclusion
이번 논문에서, 우리는 새로운 신경망 구조를 제안했다.
그것을 RNN Encoder-Decoder라 부르며 임의의 길이를 갖는 sequence로부터
임의의 길이를 갖는 (다른 집합에 속한 것도 가능한)다른 sequence로 mapping 하도록 배울 수 있는 모델이다.
RNN Encoder-Decoder는 조건부 확률적으로 sequence 쌍에 점수를 부여하는 것과
주어진 source sequence로부터 target sequence를 만들어내는 것이 가능하다.
새로운 구조를 통해 reset gate와 update gate를 통해 적응적으로
sequence를 읽거나 만드는 동안에 각 hidden unit들을 얼만큼 기억할지 또는 얼만큼 잊어버릴지를 결정하도록
새로운 hidden unit을 제안했다.
RNN Encoder-Decoder를 구문 테이블에서 각 구문 쌍에 점수를 매기는데 사용하여
SMT 작업을 통해 새로 제안한 모델을 평가했다.
질적으로, 새로운 모델이 구문 쌍에서 언어의 규칙성을 잘 파악하고
RNN Encoder-Decoder가 target 구문을 잘 만들어서 제안하는 것을 관찰할 수 있었다.
RNN Encoder-Decoder에 의한 점수들은 BLEU 수치 를 통해 전반적인 번역 성능이 개선되는 것을 찾을 수 있었다.
또한, RNN Enocder-Decoder의 기여도가 SMT 시스템에서 신경망을 이용한 접근과 꽤 독립적이라는 것을 알았다.
따라서 우리는 RNN Encoder-Decoder와 신경망 언어모델을 같이 사용함으로써
성능을 더 개선할 수 있었다.
우리의 학습된 모델에 대한 질적인 분석은
그것이 실제로 다양한 수준(단어나 문장 수준)의 언어의 규칙성을 파악했다고 본다.
이러한 내용은 RNN Encoder-Decoder로부터 이득을 얻을 수 있는 적용과 관련해
더 많은 자연어가 있을 것이라 말해준다.
고안된 구조는 분석과 개선에 있어서 큰 잠재적 능력을 가지고 있다.
여기서 조사한 것은 아니지만 어떤 접근에서는 RNN Encoder-Decoder가 제안한 target 구문을
구문 테이블의 일부나 전체를 대체하는 방법을 사용했다.
또한, 제안된 모델은 글로된 언어에만 제한되지 않고,
음성 내용같은 곳에 이 구조를 적용하는 것이 앞으로 중요한 연구가 될 것이다.