Long Short-Term Memory Based Recurrent Neural Network Architectures for large vocabulary speech recognition
Abstract
Long Short-Term Memory (LSTM)은
Vanilla RNNs의 vanishing/exploding gradient 문제를 다루기 위해 고안된 RNN구조다.
feedforward 신경망과는 다르게 RNNs는 sequence 모델링이 잘 되도록 순환적인 연결을 갖는다.
RNNs는 sequence labeling과 sequence prediction( handwriting recognition, language modeling, phonetic labeling of acoustic frames, etc.)에 사용되어 왔다.
그러나, 심층 신경망과 다르게, speech recognition에서 RNNs의 사용은
작은 규모의 phone recognition으로 제한되었다.
이 논문에서는 RNN구조를 기반으로 많은 단어의 음성 인식을 잘 학습하도록 새롭게 만든 LSTM을 소개한다.
LSTM과 RNN과 DNN 모델들을 다양한 파라미터들과 구성상태로 학습하고 비교한다.
결과적으로 LSTM은 빠르게 수렴하고 비교적 작은 크기의 모델에 최신 speech recognition 성능을 제공하는 것을 확인할 것이다.
Index Terms– Long Short-Term Memory, LSTM,
recurrent neural network, RNN, speech recognition
\(\begin{align*}\end{align*}\)
1. Introduction
Deep neural network(DNN) 같은 fedforward neural networks (FFNN)와 달리,
Recurrent neural networks(RNNs)의 구조는 현재 input에 대해
결정을 만들어내기 위해 이전 time step의 활동 또한 입력으로 받는
순환적인 feeding 형태를 갖는다.
이전 time step의 활동은 네트워크의 내부 상태에 저장되고
FFNN에서 입력으로 사용되는 고정된 맥락의 window와는 다르게
절대적이지 않은 일시적인 맥락에 대한 정보를 제공한다.
그러므로, RNN은 전체 sequence에 걸쳐 고정된 정적인 크기의 window를 적용하지 않고
역동적으로 변하는 크기의 contextual window를 모든 sequence에 적용한다.
이러한 능력은 RNN을 sequence prediction과 sequence labeling같은
sequence modeling 작업에 더 적합하게 만든다.
그러나, gradient-based 방법인 Back-propagation through time (BPTT) 기술을 이용해
전통적인 RNN을 학습 시키는 것은 vanishing / exploding gradient problem 때문에 어렵다.
게다가 이러한 문제들은 RNN이 입력과 출력 사이에 5-10개의 이산적인
tiem step을 갖는것 처럼 긴 시간에 걸친 모델이 될 능력을 제한한다.
이러한 문제들을 다루기 위해 Long-Short-Term Memory (LSTM)이 고안 되었다.
original LSTM의 구조는 recurrent hidden layer에 memory block이라 불리는 특별한 유닛이 포함되어있다.
Memory block들은 self-connection을 통해 memory cell을 포함하는데
이 memory cell은 네트워크의 일시적인 상태에 대한 정보를 저장하고 있다.
그 외에도 gate라 불리는 특정한 목표를 위해 늘어난 unit들로 구성된 구조를 추가해 정보의 흐름을 제어한다.
각 memory block은 memory cell에 흘러 들어오는 input activations를 제어하는 input gate와
네트워크의 남은 부분에 흐르는 cell activation 출력을 제어하는 output gate를 포함한다.
후에, subsequence로 segment되지 않은 연속된 입력 스트림을 처리하지 못하는
LSTM 모델의 약점을 해결하기 위해 memory block에 forget gate가 추가되었다.
forget gate는 self recurrent connection을 하는 cell에 입력되기 전에 cell의 내부 state를 scaling해서
cell의 memory를 forgetting하거나 resetting하도록 적응하는 역할을 한다.
게다가 최근 LSTM 구조는 cell 내부에서 해당 cell의 gate에 연결이 되는 peephole connections를 추가해
결과의 정확한 시간을 학습한다.
LSTM과 전통 RNN은 sequence prediction과 sequence labeling 작업에 잘 사용되어왔다.
LSTM은 문맥 자유 언어와 문맥 의존 언어에서 RNN보다 더 좋은 성능을 보여왔다.
Bidirectional LSTM 네트워크는 양방향 RNN과 비슷하고 현재 입력에 대한 결과를 계산하기 위해
TIMIT 음성 데이터베이스의 acoustic 프레임에 음성 라벨링을 하기 위해 고안되었다.
온오프라인에서 필기체 인식은 분할되지 않은 sequence data를 학습하도록
forward backward 타입의 알고리즘을 사용하는 connectionist temporal classification(CTC)를 포함하는
양방향 LSTM 네트워크들이 HMM기반 최첨단 시스템의 성능을 능가하는 것을 확인했다.
최근에는 acoustic modeling에 대한 DNN의 성공을 뒤이어,
LSTM층을 여러개 쌓은 구조인 deep LSTM RNN을
CTC output layer와 음성 sequence를 예측하는 RNN 변환기를 결합한 것이
TIMIT의 음성 인식 데이터에서 최신 기술의 결과를 보여줬다.
language modeling에서는 전통 RNN이 표준 n-gram 모델들 중에서 아주 작은 perplexity를 얻었다.
DNN이 음성인식과 많은 단어들의 speech 인식에서 가장 좋은 성능을 보이는 반면,
LSTM 네트워크의 적용은 TIMIT 데이터에서 음성인식에만 적용 가능했고
DNN보다 더 좋은 결과를 얻기 위해 추가적인 기술과
CTC와 RNN transducer 같은 추가적인 모델들의 사용이 요구되었다.
이 논문에서, RNN 구조 기반의 LSTM이 많은 단어들의 speech 인식 시스템(수천개의 문맥 의존 상태를 갖는)에서
최신 기술의 성능을 뛰어넘는것을 확인할 것이다.
큰 네트워크에서 계산적 효율의 문제점을 해결하고 model parameter를 더 잘 사용하도록
기존의 LSTM 구조를 변경하여 새로운 구조를 제안한다.
2. LSTM ARCHITECTURES
기존 LSTM 네트워크의 구조에는 input layer와 recurrent LSTM layer와 output layer가 있다.
input layer는 LSTM layer에 연결되어있고
LSTM layer에서 recurrent 연결들은 cell output unit에서 나와서
cell input, input gate, output gate와 forget gate로 바로 들어간다.
cell output units는 네트워크의 output layer에 연결된다.
표준 LSTM 네트워크에서 각 memory block에 하나의 cell은 편향을 제외하고
총 parameter W의 수가 아래와 같이 계산될 수 있다 :
$n_c$는 memory cell의 수 (여기서는 memory block의 수)
$n_i$는 input unit의 수
$n_o$는 output unit의 수
LSTM 모델을 학습시키는데 각 가중치 당 time step 별로 SGD optimizer기술에 드는 계산 복잡도는 O(1)이다.
따라서 time step당 학습에 드는 계산 복잡도는 O(W)가 된다.
비교적 적은 수의 input을 받는 네트워크의 학습 시간은 $n_c\times(n_c+n_o)$ 항목에 의해 결정된다.
많은 수의 output unit과 일시적 문맥의 정보를 저장하기 위해 많은 수의 memory cell을 필요로하는 작업에서는
LSTM 모델을 학습시키는데 계산비용이 많이 든다.
표준 구조에 대한 대안으로써 LSTM 모델을 학습시키는 데에 드는 계산 복잡도를 해결하기 위해
두 개의 새로운 구조를 제안한다.
두 구조들은 Figure1에서 보여준다.
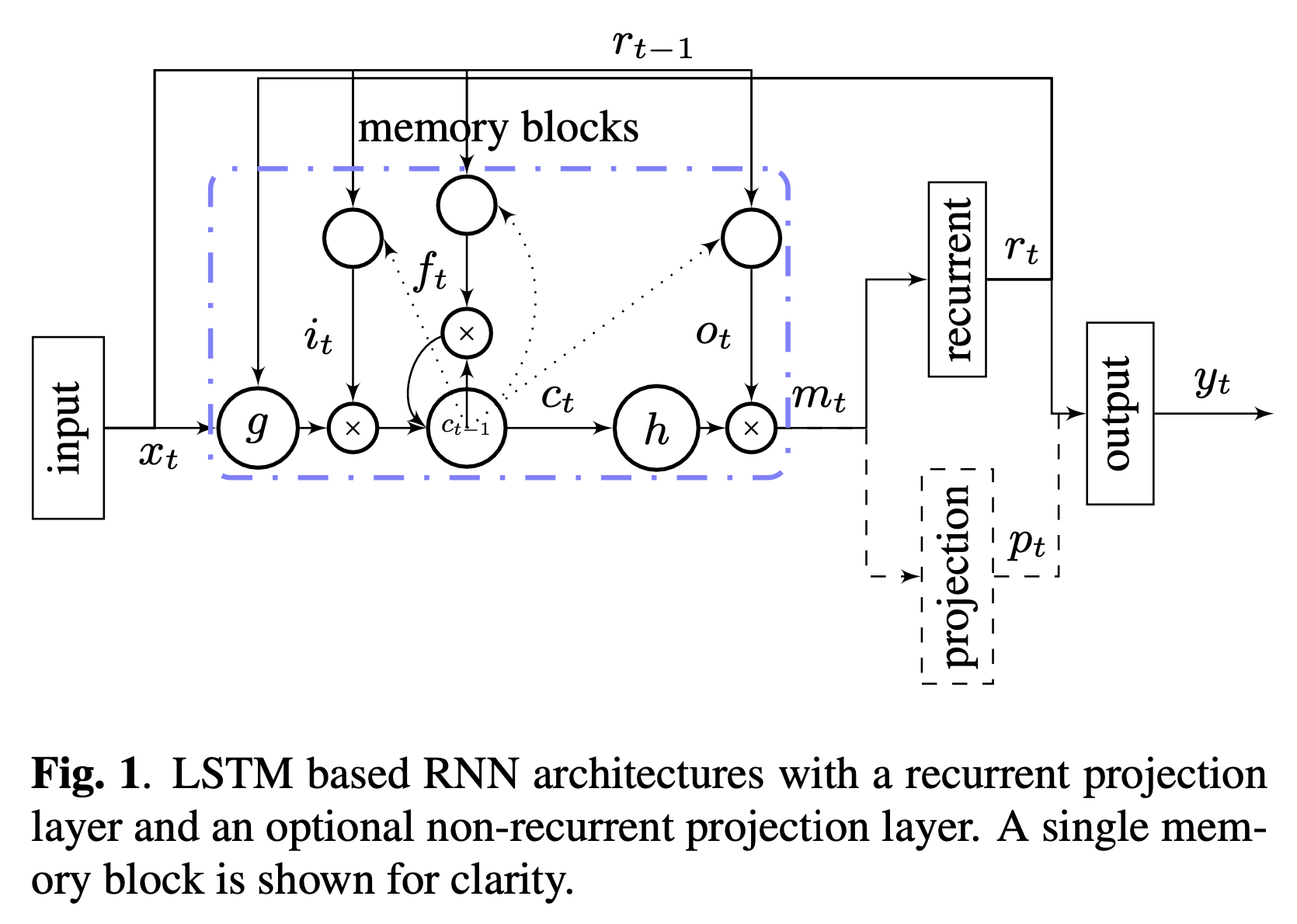
구조들중 하나는 cell output unit을 cell input unit과 gate에 연결하고
이외에도 예측 결과를 나타내는 network의 output unit에도 연결이 되어있는
recurrent projection layer에 연결한다.
그러므로 이 모델에서 파라미터의 수는
\[\begin{align*} n_c\times n_r\times 4+n_i\times n_c\times 4+n_r\times n_o+n_c\times n_r+n_c\times 3 \end{align*}\]이고 $n_r$은 recurrent projection layer의 unit의 수이다.
다른 구조 하나는 recurrent projection layer와 더불어 output layer에 직접 연결되어있는
또 다른 non-recurrent projection layer를 추가한다.
이 구조의 모델은
이고 $n_p$는 non-recurrent projection layer의 unit의 수이고
이것은 recurrent connection $(n_c\times n_r\times 4)$ 에서 파라미터의 증가 없이
projection layer의 unit의 수를 늘릴 수 있게 해준다.
여기서 output unit과 과련해서 projection layer를 두개 사용하는 것은
$n_r+n_p$개의 unit을 하나의 projection layer를 사용하는 것과 같은 효율을 보인다.
하나의 LSTM 네트워크는 아래 식을 통해 네트워크 unit들을 계산하고 주된 목적은
input sequence $x=(x_1,\dots,x_T)$를 output sequence $y=(y_1,\dots,y_T)$에 mapping시키는 것이다.
W는 가중치 메트릭스를 나타내고
b는 편향 벡터를 나타내고
sigma는 logistic sigmoid 함수를 나타내고
i,f,o와 c는 각각 input, forget, output gate와 cell vector를 나타내고
vector m과 같은 크기를 갖는다.
$\odot$은 element-wise product를 나타내고
g와 h는 cell input과 cell output activation 함수이고 일반적으로 tanh를 사용한다.
두번째 구조인 recurrent와 non-recurrent projection layer를 모두 갖는 것의 식은 아래와 같다 :
r과 p는 recurrent와 optional non-recurrent unit activation을 뜻한다.
2.1. Implementation
GPU를 사용하지 않고 하나의 기계에서 multicore CPU를 사용해서 새로 고안한
LSTM 구조를 구현했다.
이러한 결정은 CPU의 비교적 쉬운 구현 복잡도와 디버깅이 쉬운점을 기반으로 내려졌다.
만약 큰 네트워크의 학습 시간중에 하나의 기계에서 병목을 일으킨다면
CPU에서의 구현은 큰 군집의 기게에서 쉽게 구현되어 작동할 것이다.
매트릭스 연산은 Eigen matrix library를 사용했다.
이것은 C++라이브러리를 통해 CPU에서 벡터 명령어(SIMD - single instruction multiple data)를 통해
효율적인 매트릭스 연산을 하도록 한다.
활성함수와 gradient 계산의 구현은 SIMD 명령어를 통해 병렬적 구조의 이점을 얻어도록 구현했다.
Asynchronous stochastic gradient descent(ASGD)를 최적화 기술로 사용했다.
gradient에 의한 파라미터 업데이트는 비동기적으로 처리되고 multi-core 기계 상에서
multiple threads를 통해 계산된다.
각 thread는 효율성을 위해 sequence의 batch상에서 병렬적으로 연산한다.
예를 들어 vector-matrix 연산 보다 matrix-matrix 연산을 하고
더 나아가 모델 파라미터가 여러 input sequence에 의해 동시에 업데이트 되기 때문에 stochasticity한 점도 있을 것이다.
이 외에도 하나의 thread에서 sequence를 batch로 처리하게되면,
multiple thread를 동반한 학습은 더 큰 batch를 sequence에 적용할 때
병렬적으로 처리되기 때문에 더 효율적이다.
모델 파라미터를 업데이트하기 위해 truncated backpropagation through time(BPTT)를
학습 알고리즘으로 사용한다.
고정된 time step $T_{bptt}$ 예를 들어 20의 값으로 사용해서
activation을 forward-propagate 시키고 gradient를 backward-propagate 한다.
학습 과정에서 input sequence를 $T_{bptt}$의 크기인 subsequence로 나눠서 vector로 만든다.
말에 대한 subsequence들은 원래 자신의 순서로 처리된다.
우선 첫 time step부터 이전 time step까지 activation과 네트워크 입력을 가지고
반복적으로 activation들을 계산하고 forward-propagate한다.
그리고 네트워크의 error는 네트워크의 cost function을 이용하여 각 time step별로 계산한다.
그다음에 cross-entropy 기준으로 gradient를 back-propagate하는데
각 time step별로 error값과 다음번의 time step을 이용해 gradient값을 구한다.
이 때 time step은 $T_{bptt}$부터 시작한다.
마지막으로 네트워크의 가중치들의 graident값들은 $T_{bptt}$ time step동안 축적되고 그 가중치들이 업데이트된다.
각 subsequence를 처리하고 난 후 Memory cell의 상태는 다음 subsequence를 위해 저장한다.
다른 입력 sequence들로부터 여러개의 subsequence를 처리하는 경우에는
모든 sequence들의 마지막까지 도달해야 하기 때문에
몇개의 subsequence들은 $T_{bptt}$보다 짧은 time step을 갖을 수 있다.
subsequence는 다음 batch에서 새로운 입력 sequence의 subsequence로 대체되고
cell state를 reset한다.
3. EXPERIMENTS
Google English Voice Search라는 많은 단어가 쓰이는 speech recognition 작업에서
DNN, RNN과 LSTM의 성능을 평가하고 비교한다.
3.1. Systems & Evaluation
모든 네트워크들은 익명이고 손으로 번역된 Google voice search와 dictation traffic으로
구성된 데이터셋에서 1900시간동안 300만개의 말을 학습했다.
데이터셋은 10ms마다 계산되고 40차원을 가지는 25ms로 표현된다.
말들은 14247개의 CD(문맥 의존) state를 갖는 9000만개의 가중치로 구성된 FFNN에 배치된다.
출력 상태를 세개의 다른 목록으로 적용하며 네트워크들을 학습시켰다 : 126, 2000 and 8000
이것들은 14247개의 state들을 동일한 클래스를 통해 각자의 작아진 목록으로 mapping시켜서 얻는다.
126 state set은 Context independent(CI,문맥 독립) state (3 x 42)이다.
학습하기 전에 모든 네트워크의 가중치들은 임의로 초기화시켰다.
learning rate는 각 네트워크와 구성에 맞게 안정한 수렴 결과를 얻기 위해 설정했다.
learning rate는 학습하는 동안 기하급수적으로 줄었다.
학습하는 동안 200000 프레임 set에서 frame accuracies를 평가했다.
다시말해 phone state labeling accuracy acoustic frame 같은 것이다.
학습된 모델드른 23000 손으로 번역된 말들로 이루어진 음성인식 시스템에 대한 test set으로 평가했고
word error rates(WERs)도 계산했다.
언어 모델에서 decoding에 사용된 단어들의 크기는 260만개이다.
DNNs들은 200개의 프레임으로 배치를 적용해 GPU환경에서 SGD를 통해 학습했다.
각 네트워크는 logistic sigmoid 은닉층과 phone HMM state를 나타내는
softmax output layer와 전결합을 이루고있다.
LSTM 구조에서도 일관성을 위해 어떤 네트워크들은 low-rank projection layer를 갖는다.
DNN의 입력은 5 frame을 오른쪽에 10이나 15 frame을 왼쪽에 쌓아(10w5, 15w5)로
비대칭적인 window의 구성으로 이루어진다.
LSTM과 전통적인 RNN의 다양한 구성들은 각 thread가 각 utterance에서 step별로
4개나 8개의 subsequence의 gradient를 계산하도록하여
24개의 thread로 ASGD 기법을 사용해 학습되었다.
20번째 time step ($T_{bptt}$)이 activations의 forward-propagate와 truncated BPTT 학습 알고리즘을
gradient의 backward-propagate를 위해 사용되었다.
RNNs의 은닉층의 unit들은 logistic sigmoid activation function을 사용했다.
Recurrent projection layer구조를 갖는 RNN은 projection layer에 선형 activation unit을 사용했다.
LSTM은 tanh를 cell inpu unit, cell output unit과
input, output forget gate의 logistic sigmoid 활성함수로 사용했다.
LSTM에서 recurrent projection layer와 optional non-recurrent projection layer에서
선형 activation unit을 사용했다.
LSTM과 RNN에 들어가는 입력은 40차원의 25ms 프레임이다.
앞으로 들어올 frame에 대한 정보는 현제 frame에 대해 더 좋은 결정을 하도록 돕기 때문에
output state label을 5 frame 연기시킨다.
3.2. Results
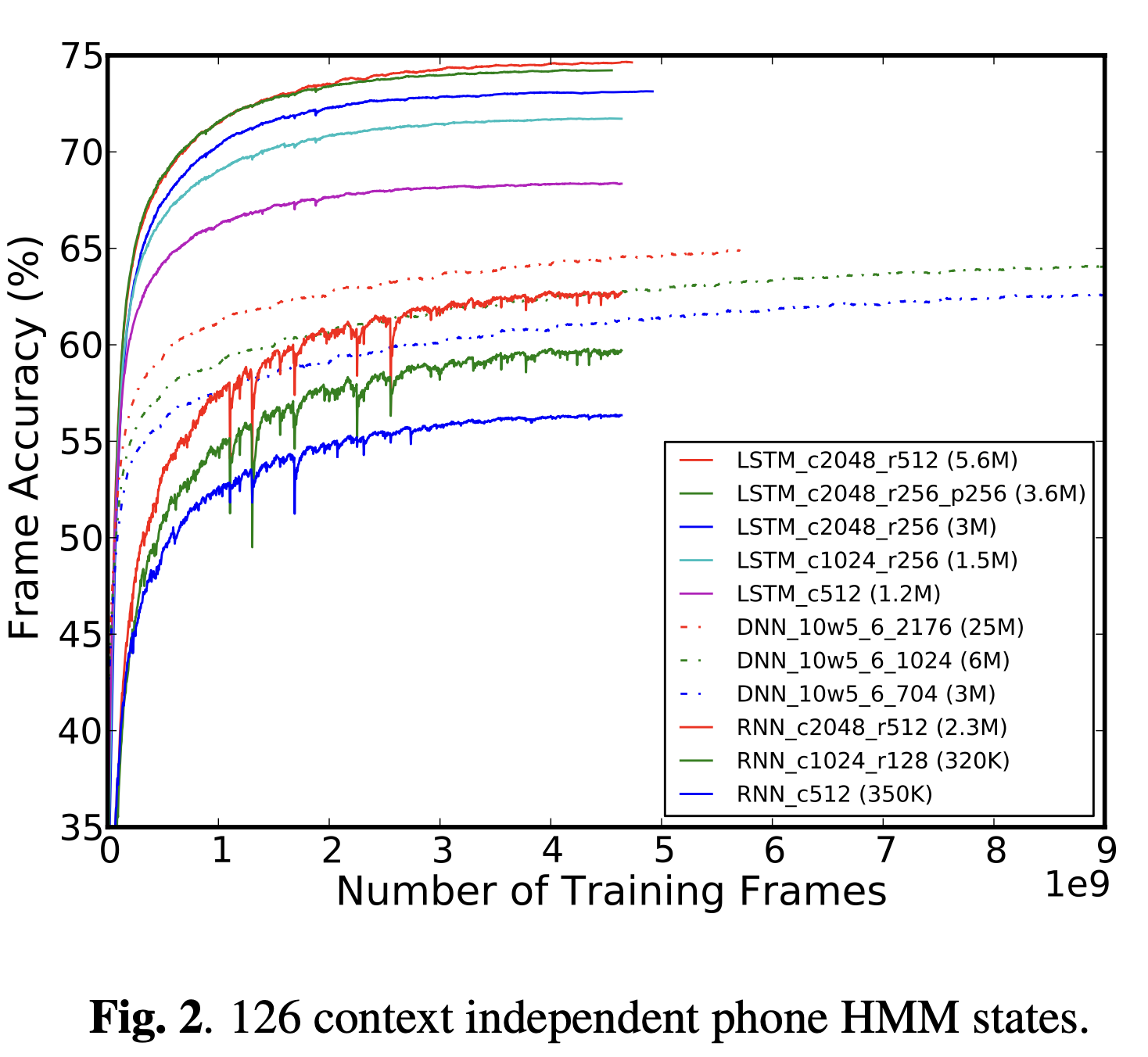
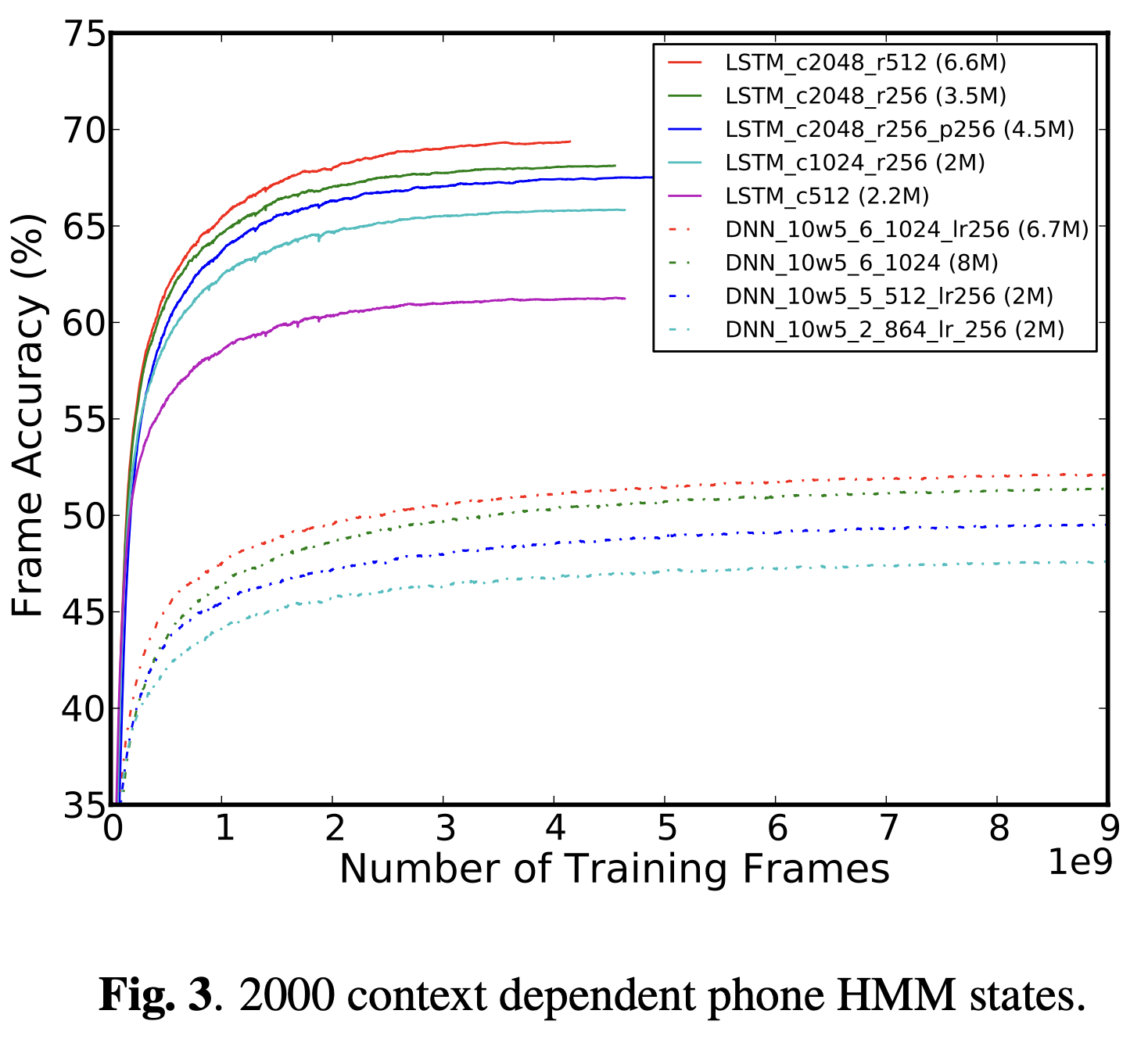
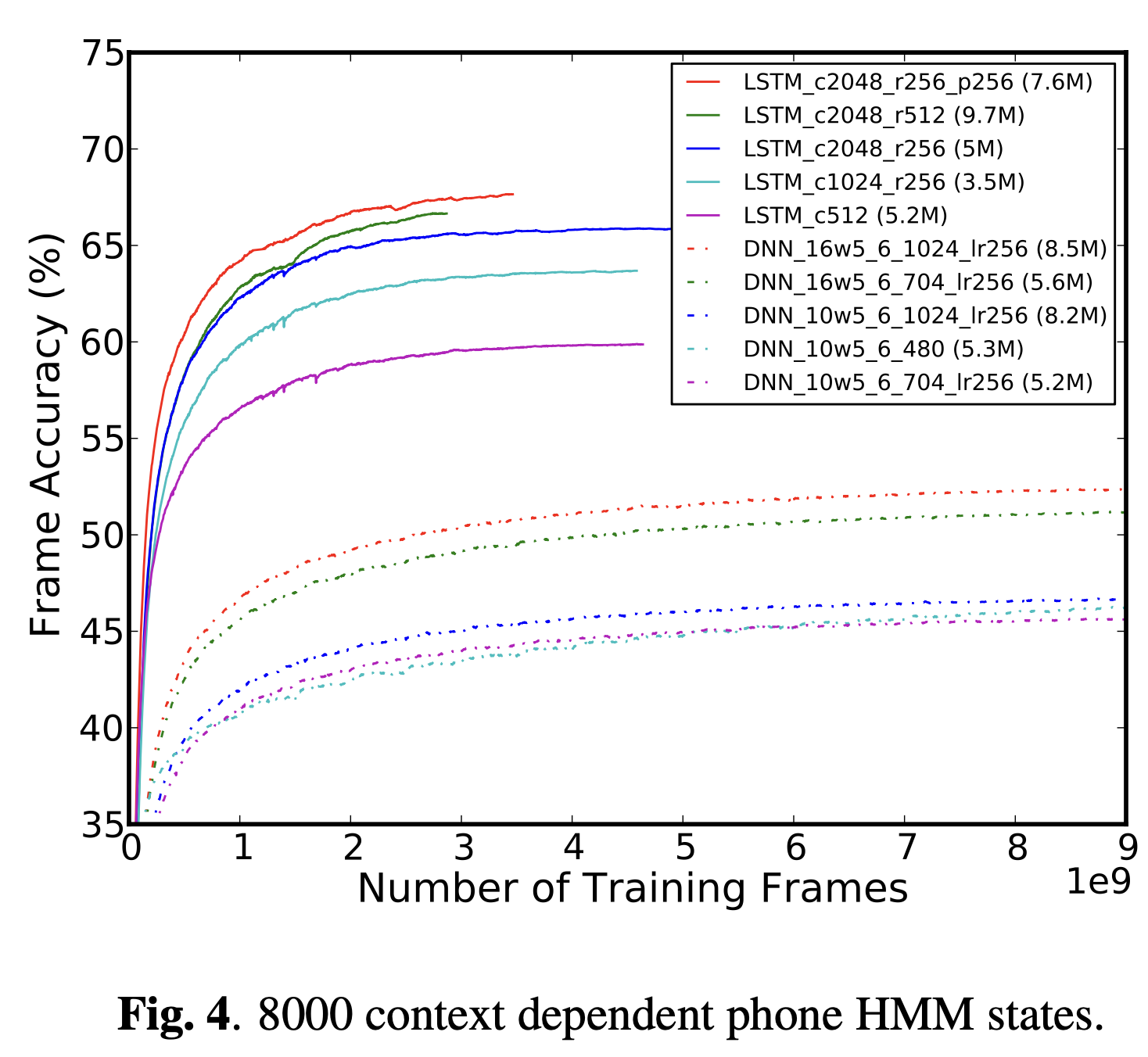
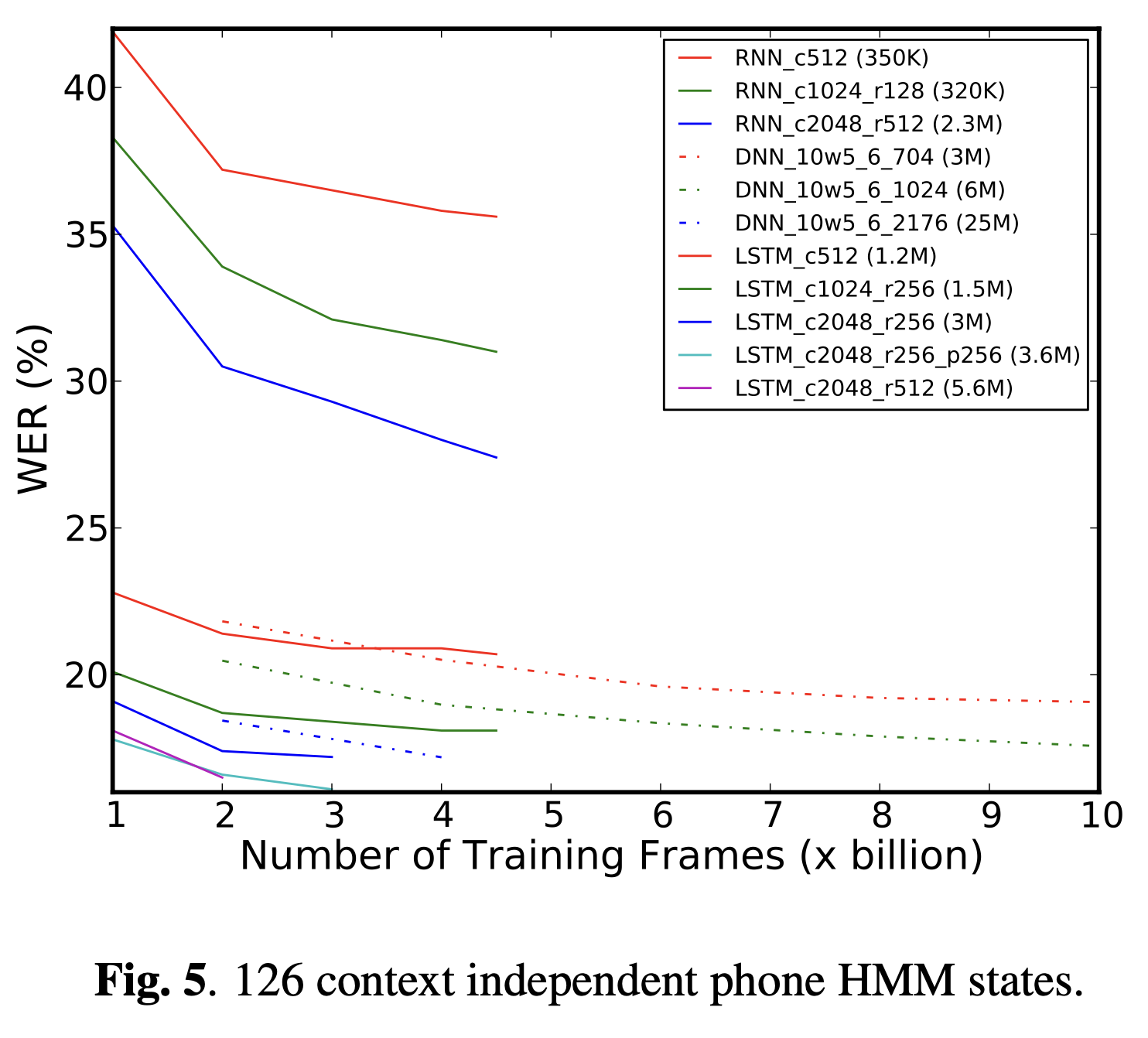
Figure 2,3 과 4에서 각각 126, 2000과 8000 state output에 대해 frame accuracy를 보여준다.
Figure에서 네트워크 구성의 이름은 네트워크 크기와 구조에 대한 정보를 갖고있다.
cN에서 N은 LSTM에서는 memory cell의 수를 뜻하고 RNN에서는 은닉층의 unit 수를 뜻한다.
rN은 LSTM과 RNN 모두 recurrent projection unit의 수를 뜻한다.
pN은 LSTM에서 non-recurrent projection unit을 뜻한다.
DNN 구성의 이름은 10w5처럼 왼쪽과 오른쪽의 context size를 뜻하고
은닉층의 수와 각 은닉층의 unit 수
그리고 optional low-rank projection layer의 크기를 뜻한다.
괄호 안에는 각 모델의 가중치의 수에 대한 정보가 담겨있다.
RNN이 126개의 state output에서만 실험된 이유는
126개의 state output에 대한 결과에서 이미 DNN과 LSTM보다 훨씬 뒤쳐지는 성능을 보였기 때문이다.
Figure 2에서 보이듯 RNN들은 매우 학습 초기에 매우 불안정한 모습이고
수렴하도록 하기 위해 exploding problem 때문에 activation과 gradient를 제한했다.
LSTM은 빠르게 수렴하면서 RNN과 DNN보다 더 높은 frame accuracy를 보였다.
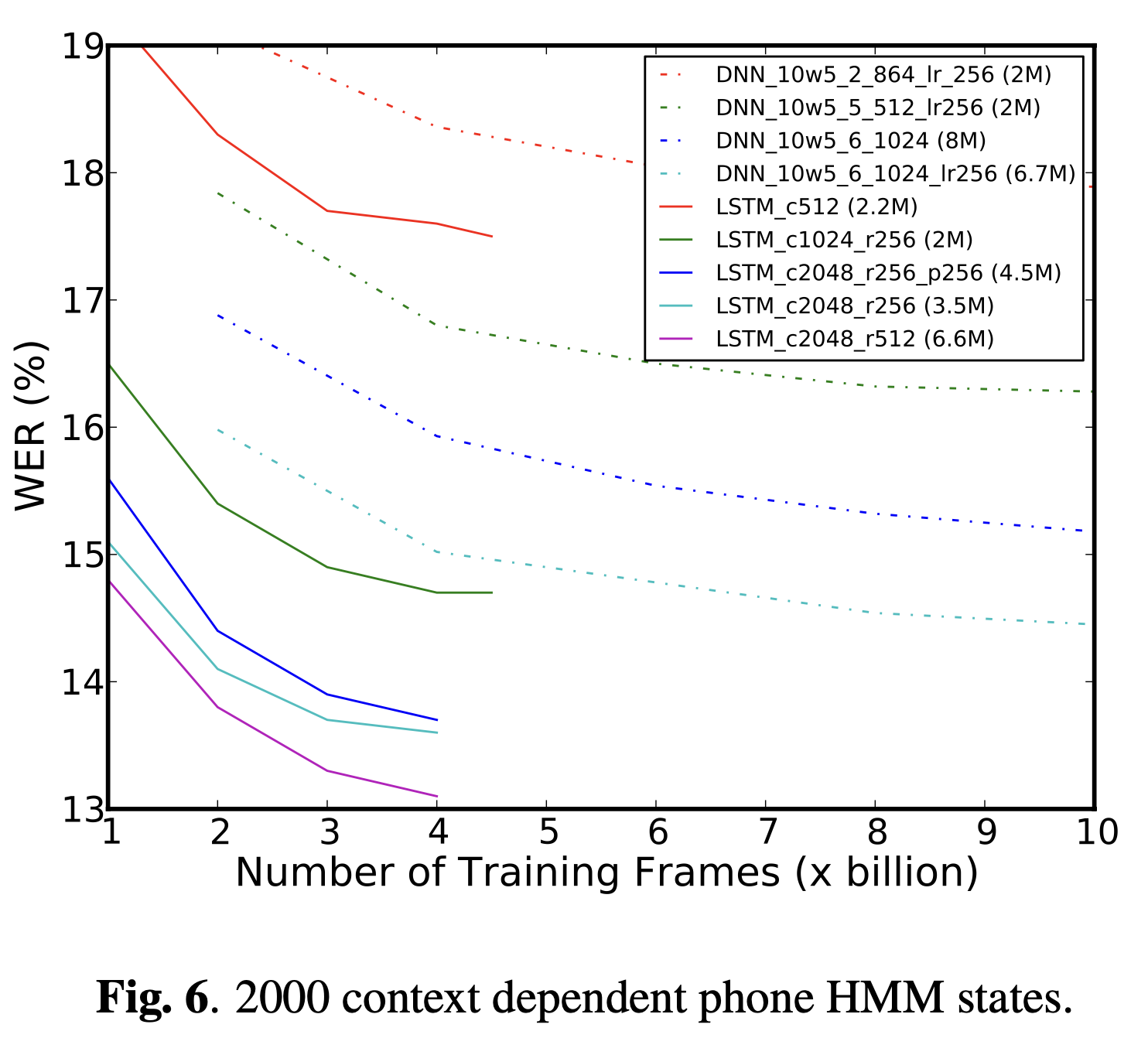
Projected RNN구조를 통해 고안된 LSTM은 같은 수의 파라미터를 적용했을 때
기존 RNN기반 LSTM보다 더 높은 accuracy를 보였다.
(Figure3에서 LSTM_512 vs LSSTM_1024_256)
Recurrent와 non-recurrent projection layer를 포함하는 LSTM 네트워크는
recurrent projection layer만 포함하는 LSTM보다 일반적으로 더 좋은 성능을 보였다.
단, 2000개의 state를 적용한 경우는 learning rate를 너무 작게 설정했기 때문에 다른 결과가 나왔다.
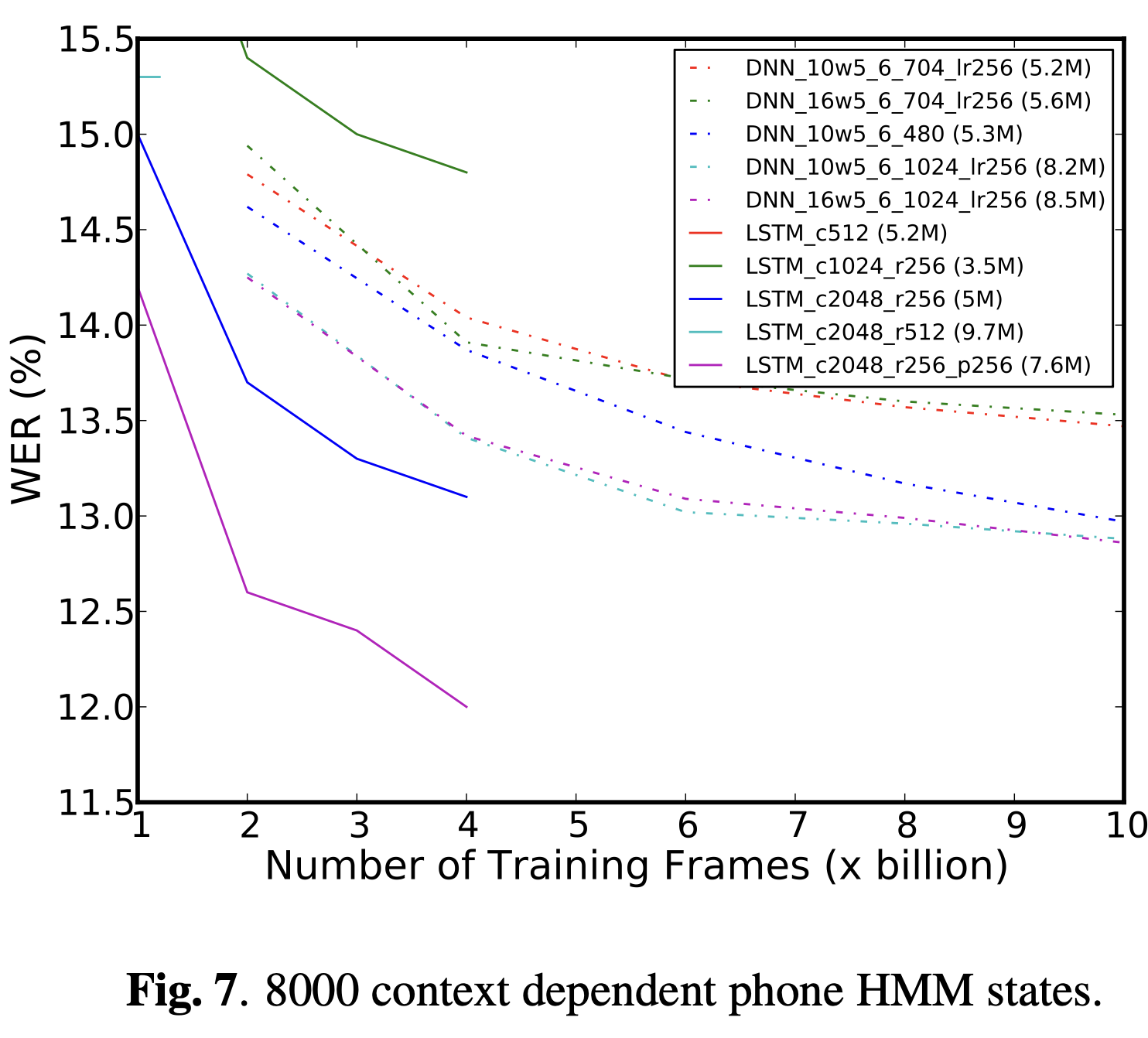
Figure 5, 6과 7에서는 126, 2000과 8000 state output에 대해 같은 모델별로 WERs를 계산했다.
아직 몇몇 LSTM 네트워크들이 수렴하지 않은 상태이지만, 논문의 마지막 개정에서는 완성 시키도록 할 것이다.
음성 인식 실험에서는 문맥 의존적인(CI) 126 output state모델,
CD 2000 output state embedded size model(mobile phone processor에서 작동하기 위해 제한됨)
그리고 비교적 큰 8000 output state에서 LSTM 네트워크가 정확도가 개선되었다.
Figure 6에서 보듯, LSTM_c1024_r256과 LSTM_c512를 비교해보면
새로 고안된 구조가 RNN보다 더 좋은 인식 정확도를 얻는데 필수적이라는 것을 알 수 있다.
또한 DNN의 깊이가 중요하다는 것을 보이기 위한 실험도 했다.
(Figure 6에서 DNN_10w5_2_864_lr256과 DNN_10w5_5_512_lr256을 비교해라)
4. CONCLUSION
이미 알듯이 이번 논문에서 LSTM 네트워크를 large vocabulary speech recognition 작업에 적용해 보았다.
큰 수의 output unit을 사용하는 큰 네트워크에 LSTM을 적용할 수 있는 확장성을 위하여,
기존 LSTM 구조보다 모델 파라미터를 더 효율적으로 사용할 수 있도록 새로운 두가지 구조를 만들어 소개했다.
그중 하나는 LSTM layer와 output layer 사이에 recurrent projection layer이 들어간 구조이고
다른 하나는 추가적인 recurrent 연결 없이 projection layer를 추가하기 위해 non-recurrent projection layer를 추가한 구조로
이렇게 분리하면 유연성을 얻을 수 있다.
새로 고안된 구조들이 기존 LSTM에 비해 더 좋은 성능을 보인다고 확인했다.
또한, large vocabulary speech recognition 작업에서 더 많은 output state를 사용할 때
새로 고안한 LSTM 구조가 DNN보다 더 좋은 성능을 보이는 것을 확인했다.
LSTM을 single multi-core machine에서 학습 시키는 것은 더 큰 네트워크로 확장할 수 없다.
후에 GPU와 분리된 CPU에서의 구현을 연구해 볼 것이다.